Using a tool like Bollinger Bands® to forecast future price ranges is a time-honored technique but its calculations are simplified and in some situations flawed. Incorporating the log-normal nature of stock prices into the calculations gives better answers.
One greed-inducing aspect of volatility is that it enables us to make theoretically sound forecasts about the future. It doesn’t matter whether it’s stock prices, annual rainfall, or deaths by shark attack, we can often use past volatility as a way of quantifying the probability of future values. Volatility doesn’t enable us to predict whether average values are going to go up or down (sometimes we can use long-term averages for that) but it does allow us to make statistically valid predictions of the plus/minus ranges we can expect. Of course, there are assumptions (e.g., that the level of volatility remains stable) but typically those are reasonable baselines.
Techniques like Bollinger Bands®, Probability Cones, and Z-scores use simplified calculations for computing price ranges. For low levels of volatility and relatively short time periods their errors are small but as time and volatility increase your results can be significantly wrong or even nonsensical. Given that institutional money is at stake, option pricing techniques such as the Black-Scholes equation and binomial tree calculations don’t take such shortcuts.
The incorrect assumption of the simplistic calculations is that since plus and minus returns are typically symmetrical, price ranges are symmetrical too. As a simple counterexample, consider the end results for two symmetrical sequences of returns: three +2% days in a row, versus three -2% days in a row. In the uptrend case, the final price increase factor would be (1+.02)3 = 1.0612, 6.12% higher than the starting price, and the downtrend price would be (1-.02)3 = 0.9412, 5.88% lower. Not symmetrical!
Enter the Lognormal
As a result of this asymmetry, values of tangible things like stock prices, rainfall, and shark attacks that can’t go below zero often end up having what’s called a log-normal distribution. These distributions are skewed to the right with a fatter right tail and a truncated left tail.
The chart below is a histogram showing the distribution of annual rainfall in Boulder Colorado for the last 123 years.
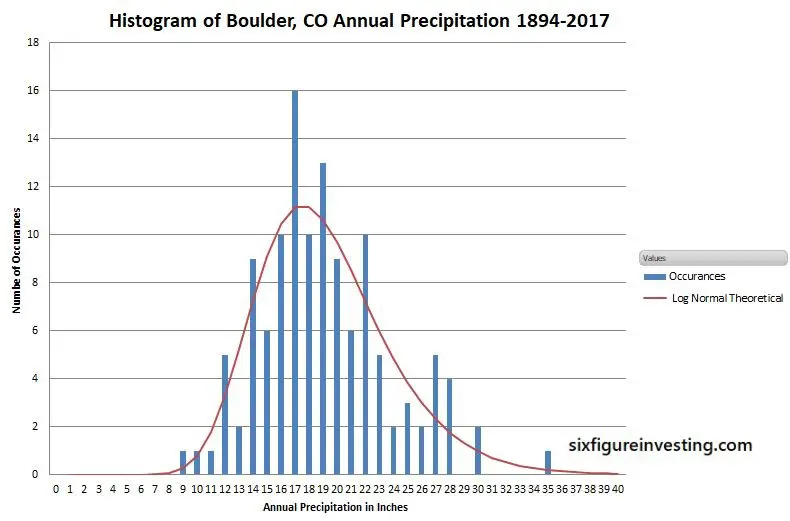
The horizontal axis has one-inch bins for annual rainfall (e.g., 12.3 and 12.8 would both go into the “12” bin) and the vertical axis is the number of occurrences of yearly rainfall that landed in that bin).
The red line calculation uses the volatility of annual rainfall along with log-normal statistics to predict Boulder’s annual rainfall distribution—not a bad match to the historical data.
Historical price distributions of stock prices generally don’t have a log-normal shape because there’s another confounding factor—long-term growth. The average annual rainfall in Boulder hasn’t changed much in the last 123 years but stock prices are usually different—the stocks that stick around tend to grow. Persistent growth smears out the price distributions over time. Illustrating that, the chart below shows the simple histogram of S&P 500 prices since 1950—no log-normal in evidence.
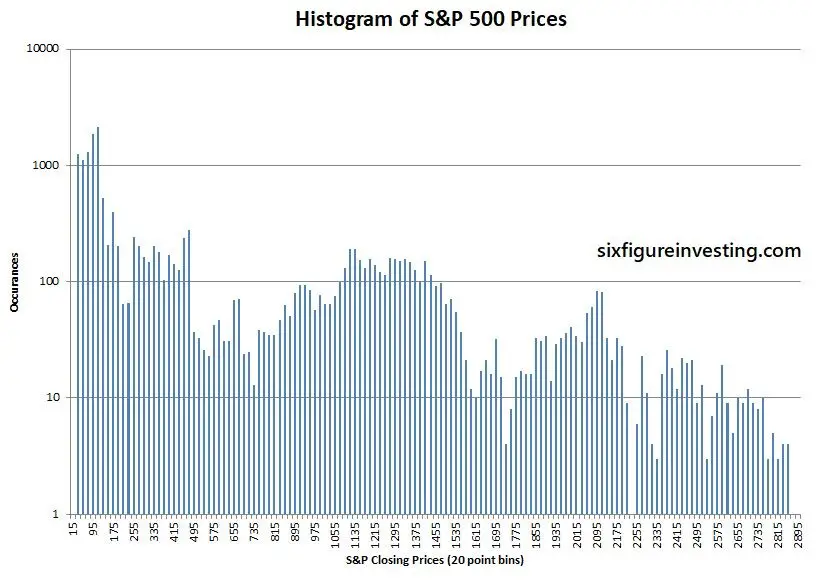
We can remove the impact of growth by adjusting the price data with the time-series’ average growth rate—this is a calculation similar to using historic inflation rates to adjust for the buying power of a currency.
In the case of the S&P 500 the compounded growth since 1950 has been 0.0295% per day. If we compound that value daily we obtain a factor that adjusts the price for the constant growth component of the S&P 500. For example, the April 5th, 2018 S&P index closed at 2662.84. We can remove the cumulative average growth from that value by dividing it by the compounded average growth factor (1+0.000295)17175 = 158.52, where the 17175 is the number of trading days since January 3rd, 1950. The adjusted price is thus $16.80. Applying this adjustment technique to the entire S&P 500 daily time series we get the price distribution chart below:
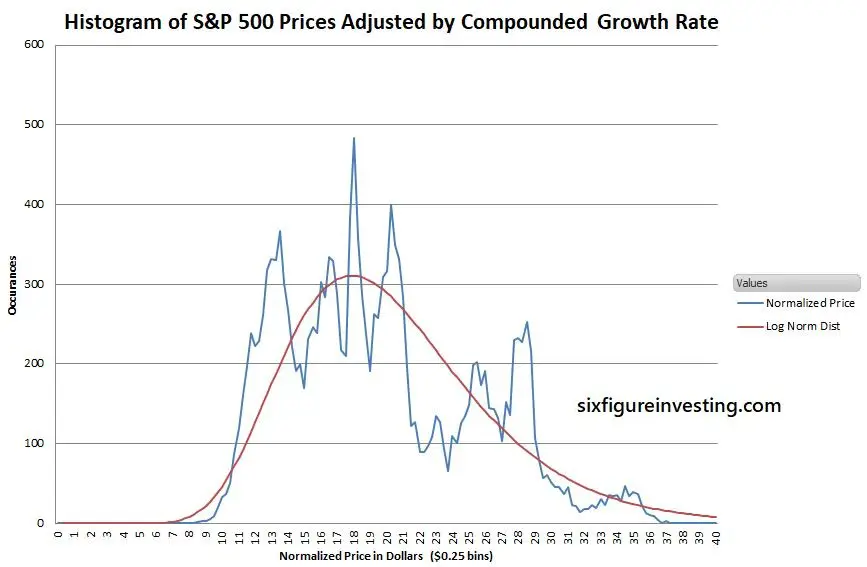
Not pretty—but recognizably log-normal.
When trying to predict future price ranges the analysis needs to take into account that stock prices are log-normally distributed—not Gaussian.
Transforming the Log-normal
Mathematically, dealing directly with log-normal distributions is ugly. To simplify things the standard approach uses a mathematical transform. A good transform converts a problem that’s tough to solve with default techniques into a different framework where the problem is easier to solve. For example, it’s tough to physically copy a shirt directly (absent a suitable 3-D printer) but if the shirt is transformed—taken apart at the seams, the resulting pieces of cloth can be used to make a two-dimensional pattern. With a pattern, it’s easy to make copies. In the case of log-normal distributions, the logarithm function or “log” for short is the transformational equivalent of seam ripping.
If you take the log (usually base e, known as the natural logarithm LN) of each data point in a price history, you transform the distribution from a log-normal one into a normal one—we are now in “Log World”. Standard statistical tools can now be used with this normal distribution.
However, this first step doesn’t solve the problem of growth smearing the data—we resolve that by utilizing the period to period differences (returns) rather than the log prices. You can write this step as ln(Pn) – ln(Pn-1), where n equals the period number. Mathematically these log and return calculations can be combined into one compact operation: ln (Pn /Pn-1). This formula is often called the “log-returns” calculation. When we convert stock price histories into log-returns we get nice symmetric distributions suitable for forecasting. The chart below shows the log-returns distribution for the S&P 500.
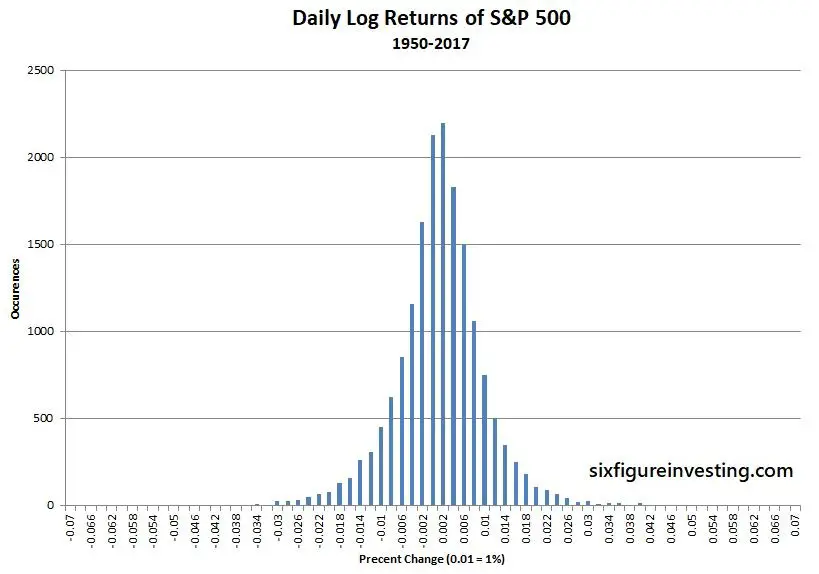
Now, in preparation for doing our price projections, we can compute the statistical average growth rate (mean) and the volatility of this distribution using standard tools applicable to Gaussian distributions. The average of the log returns is the geometric mean (the continuously compounded version), which I’ll call GMCC. The volatility of the returns is computed by taking the sample standard deviation of the log returns. Be aware that both of these numbers were computed in Log World so they don’t directly relate to prices. Also, be aware that volatility is usually quoted in annualized terms—which enables apples-to-apples comparisons between different securities or time period lengths. However for the calculations that follow we must keep the time period of the mean and standard deviation the same as the data set being used (typically daily).
Projecting Some Prices—the Median Forecast
Now that we have the key parameters we can move on to predicting some prices.
The simplest prediction is the median price. Statistically 50% of the time the actual closing price will be higher than the forecasted median price and 50% of the time the actual price will be lower. The formula for the forecasted median price is:
Pn = Ps* e(GMcc*n)
Where:
- Pn = median price n periods in the future
- Ps = starting price
- e = Euler’s number ( approximately 2.71828) , in Excel use the EXP() function
- GMcc = Geometric Mean (continuously compounded version)
- n = desired number of trading periods in the future for the forecast
So, for example, using historic parameters for the S&P 500, if the S&P is at 2900 and you want to estimate the median price point 21 trading days in the future the answer would be:
P21 = 2900 * e(.000295*21) = 2918 (+0.62%)
The “e” in the “e(GMcc*n) “ part of the equation converts things from “Log World” back to log-normally distributed prices. It’s the equivalent of what a sewing machine does in my clothing analogy—transforming pieces of cloth back into real-world clothing.
The key assumptions are that the log-returns are normally distributed and that the geometric mean stays stable. If the average growth rate of the stock starts trending up or down then all bets are off.
The trading period can be any consistent period of time—days, minutes, months, etc. The only restriction is that the geometric mean and standard deviation need to be computed using data with the same period length.
Enter Volatility
For a median price estimate, we only need the geometric mean but traders and investors are often interested in probabilities other than 50-50. To make those estimates, we also need to know the estimated volatility of the underlying security. The volatility is a key component because it quantifies how widely a price is likely to diverge from its current price —for example, the odds of a low volatility utility stock increasing 10% in the next month might be quite low but a volatile tech stock might easily move that much or more.
The probabilities associated with volatility have a fixed relationship to the standard deviation. For example, if returns are normally distributed the probability of a stock’s one-day percentage up move exceeding one standard deviation (+1 sigma) is ~16% and the odds of it exceeding a two standard deviation move (+2 sigma) is ~2.23%. The generalized equation, which adds a volatility term, predicts upside price points over time:
Pn = Ps * e(GMcc*n+k*stdev*square root (n))
Where:
- stdev = sample standard deviation of the log returns (in Excel: STDEV.S())
- k = multiplication factor, where 1 = 1 sigma, 2 = 2 sigma
Yes, that square root of the number of periods in the added volatility term is weird. See Volatility and the Square Root of Time for more on that topic
For the sake of convenience, we usually use integer values of k but if you need different probabilities (e.g., quartiles) it’s straightforward to compute them. For example, if you need to know the price that will not be exceeded 75% of the time k is +0.67, for 90% the k factor is +1.28.
If we want to want to compute a S&P index value that should statistically only be exceeded 16% of the time, (+1 standard deviation or one sigma) 21 days from now, we can compute:
P21+16% = 2900 * e(0.000295*21 + 1* 0.01*square root (21)) = 3054.85 (+5.34%)
If we want to compute the upside S&P price 21 days from now, that only has a 2.23% chance (+2 sigma) of being breached, we compute:
P21+2.5% = 2900 * e(.000295*21 + 2* 0.01*square root (21)) = 3198.10 (+10.28%)
The Downside—Similar but not Symmetrical
The downside equation is similar but instead of adding the volatility term we subtract it.
Pn = Ps * e(GMcc*N – k* stdev*square root (n))
If we want to want to compute a downside S&P index value that should statistically only be breached 16% of the time (-1 standard deviation or minus one sigma) 21 days from now we compute:
P21-16% = 2900 * e(0.000295*21 – 1* 0.01*square root (21)) = 2787.3 (-3.89%)
Because of the log-normal nature of stock prices, the downside percentage for a -1 sigma move is less than the 1 sigma upside move.
The key assumptions for these equations are the same as the median prediction with the additional restriction that the volatility of the stock stays consistent. If volatility really picks up or fades then all bets are off.
Making Things Simpler—but Sometimes Too Simple
Popular and useful tools like Bollinger Bands®, Probability Cones, and Z-scores use a simpler approach. Usually, they assume the median price forward is today’s price and leave out the exponential function. Their approach to projecting price ranges is to increase it from the starting price by +k*stdev* square root(n) and decrease by –k*stdev* square root (n). These simpler formulas are reasonable if durations are short (e.g., 2 months or less) and volatilities, as well as sigma levels, are low. For the S&P 500, the typical error on the median price for 21 trading days would be around -0.5%, and the 1 sigma price bands errors will be around 2.2%.
On the other hand, if you are using higher sigma levels (e.g., Bollinger Bands default to 2), longer periods of time, larger geometric means, and/or securities with high volatilities (e.g., TSLA, NFLX, VXX, UVIX, SVIX, UVXY) then the errors become significant. For example, the 2X leveraged volatility fund, Volatility Shares’ UVIX—typically has a large geometric mean (e.g., -0.5%), and a high standard deviation (e.g., 4%). With those characteristics, the error using the simplified calculation after 21 days on the median is -5%, the one sigma high/low band errors are -3% and 15%, and the 2 sigma high/low ranges have errors of -12% and +25%.
Monte Carlo Simulation Validation
As a cross-check of this analysis, I ran a Monte Carlo simulation of a test stock similar to Google (GOOG) with a daily geometric mean (.07%) and standard deviation (2%). The simulation models the “random walk” behavior of a stock with the specified characteristics.
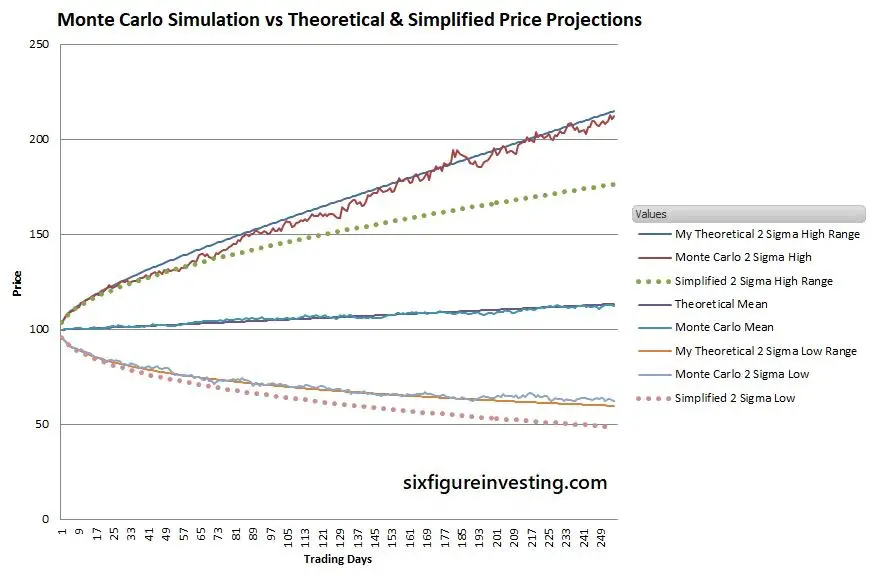
The smooth solid lines for high and low ranges are my two sigma theoretical projections. The Monte Carlo lines show the first high and low simulated prices that are at the two sigma probability ranges (2.23%) for each period. The dotted lines are the simplified estimates for high and low ranges using a Bollinger Band style analysis.
As you can see, the simplified analysis significantly underestimates the statistically expected ranges—after a year the predicted high range is 33% low and the low range is 28% low.
Conclusion
When the accuracy impact is low, it’s reasonable to simplify calculations to make them less intimidating or reduce the computational burden but it’s important to understand when those simplifications aren’t appropriate. When habitually using these oversimplifications not only do all the results become suspect, it also hinders our understanding of what’s really going on.
For anyone looking into the finer points of volatility-based price forecasts the equations incorporating the log-normal distribution of prices should be used. Don’t create unnecessary distortions in your crystal ball.
Hello. I was wondering, for the final “Daily Log Returns of S&P 500” plot, one could say its approximately normal, but is it not leptokurtic?
Hi Ed, A close look reveals that it is definitely leptokurtic. It turns out that the Laplace distribution is a significantly better match to the S&P 500 log returns than the normal distribution. https://www.sixfigureinvesting.com/2016/03/modeling-stock-market-returns-with-laplace-distribution-instead-of-normal/
Best Regards,
Vance
Ah, very interesting. Thanks so much for the replies!
Hi Vance. Hope all’s well with you.
I came across a discussion of value-at-risk in a book where, for the parametric or mean-variance form, they’re using daily log returns to calculate the standard deviation. Then, they’re multiplying the exposure (assume $1M long of whatever) by that standard deviation (assume 1%), and lastly multiplying that value by the one-tailed Z score (assume 1.65 for 95% confidence) to derive the 1-day, 95% VaR (here it’s $16,500).
Now, firstly, I noticed they omitted using the mean of the returns despite basing the standard deviation on a relatively short, 20-day lookback, where you could certainly have a significant mean return especially if a diminutive standard deviation is involved (notwithstanding the obvious shortcomings of using such a short lookback).
Secondly, when multiplying the exposure by the log return-derived standard deviation, aren’t they still in ‘log land’ – as you say? Wouldn’t it be correct to first transform back to simple price by: (e^(1.65*-1%)) * asset price, and then deriving the real world simple percentage price change?
As in, assuming the asset price is $50, e^(1.65*-1%) = 0.9836; and $50 * 0.9836 = $49.18; and $49.18/$50-1 = -1.64%; and $1M * -1.64% = $16,400; where I multiply the standard deviation by the Z score.
For low realised volatility environments, I realise the difference between simple and log returns is going to be minimal. But if the standard deviation is larger, the VaR dollar amount is actually going to be distorted especially if the exposure is large, using the method in this book.
I also think the mean should be considered, as you illustrate, when the lookback is small. If the lookback is large; a year or multiple years of daily data, then the mean will normally be close to zero and I understand not using it in that case.
Historical or non-parametric VaR is more widely thought to be more practical if using an entire price history. But even that can be limited if the asset is a new issue.
Was hoping you could share a thought on this which I would very much appreciate. Are they wrong to not transform back from log land? My thought was if they’re doing what they’re doing, better off using simple returns? Thank you. Kevin Laffey
Hi Kevin,
So with the VAR calculation I assume the ultimate goal is to determine if the exposure level exceeds a threshold, and if so reduce exposure via reduced leverage, adding hedges, etc. This is not my area of expertise, so don’t put a lot of faith in my observations.
Using the standard deviation of log returns vs straight returns for equity style markets will be a pretty small adjustment, it would however tend to accentuate negative returns so that’s good from a risk management standpoint. Regarding the mean, I assume you mean the drift factor that the security has been showing, e.g, averaging 0.003% per day upward trend. I would be surprised if they did include the mean, because it doesn’t significantly impact the overall risk factors, which would be orders of magnitude more important. In any event the drift would be really noisy, following minor market moves and only interesting when expanded out into month long or longer time periods.
Regarding multiplying the exposure by the volatility, I would say the log vs simple volatility differences would be very small, more important I think would be that the actual price action is going to be
Pk = Pk-1 *e^(volatility), which exponentially weights the price action. This would describe normal market action more accurately, however from a risk management standpoint the down side estimates of volatility tend to be too low, so what they suggest is actually more conservative and therefore more suitable for a risk oriented analysis.
So summarizing — log vs non-log volatility is a likely ignorable difference (assuming daily periods)
— Mean/drift factor — likely should not be not present in a risk analysis, too variable, and insignificant
I think the log/not log differences would be pretty minor, my overall comment is that most risk management analyses tend to under estimate the downside risk. This analysis is essentially a 2 sigma approach
which would likely not help much when a high sigma event (e.g, covid crash) comes along.
Call me ignorant. Call me uneducated. Call me mathematically illiterate. Say I haven’t been looking in the right places. But I’ve been a student of the markets, bumbling my way through, for nearly 30 years, and NEVER have I read a more complete, accurate, comprehensively-explained, full-picture, soup-to-nuts, easily-digested, informative writing on this topic than what is written ON THIS PAGE by Mr. Harwood.
Even a caveman like myself can clearly understand the underlying rationale for using log returns on asset prices for modeling purposes, see formulas written in plain language that convey the correct method, and witness the proof in the pudding associated with the shortcomings of the incorrect methods with what you have produced here.
My hat is truly off to you, Vance. Thank you so much!
I’ve actually used this method myself but not being a mathematician (just a back-seat mathematics and statistics tourist, really), I had never fully understood the precise reasons why – which made explaining the concept to others of course impossible. I’ve been trying to learn though, in fits and starts over the years. The concept of stationarity of the data, autocorrelation, etc. A markets acquaintance suggested I read ‘Paul Wilmot Introduces Quantitative Finance, 2nd Ed’, as a foundation, which I’m slowly working my way through.
I’m so glad and appreciative I’ve come across your website and looking forward to reading more of your articles. Going to check Amazon to see if you’ve written any books I can buy!
Hi Kevin, Appreciate the feedback, and glad it has been helpful for you. Yes, explaining this stuff to others is impossible when the very basic stuff is fuzzy. No books yet, but I might do that. I’ve been working on something for a couple of years that I think is pretty fundamental, so if that pans out there might be enough follow on material to justify a book.
Best Regards,
Vance
Hi,
Interesting article.
How do you get to the “0.000295 per day”?
Its not (2662.84-100)^(1/17175)-1, because that’s 0.000459.
Thank you,
Ben
Hi Ben,
The .000295 is the geometric return, or compounded daily return. The formula is (Pend/Pstart)^(1/N) -1 where N is the number of periods. For this calculation the Pstart was 16.66, the Pend was 2662.84 and the number of periods (days) was 17175)
The 158 is the (Pend/Pstart) — Vance
Hi Vance,
Thank you for the article.
How would you change your equations if the price shows constant rather than exponential growth?
The data I’m dealing with (accumulation of project value) has a constant upward linear trend, but includes a lot of volatility. Imagine that these are the last 6 data points showing how much project value has been delivered.
0, 24, 71, 140 ,211 , 325, 397
If I assume a linear trend with this data, 25 more periods gets me to about 2000. However, your median equation lands me at about 2000000. I’m assuming it’s because your equations assume a compounding growth?
My main goal is to have the volatility in the data reflected in the upside and downside curves your charts show.
Basically, I think want to recreate what you’ve done but eliminate the compound growth factors. I don’t know how to change your equations to achieve that. Any advice?
Hi Doug,
Yes, my analysis assumes a multiplicative process, which in a trending situation will have compounding growth. The six data points you provided aren’t a lot of data but if you’re dealing with humans creating value then a linear growth model is reasonable. A simple model would assume Gaussian distributed “noise” in the daily moves of the project value. A more realistic model for the noise might be log-normal distribution with the long tail oriented on the fall short side. Although management routinely expects miracles to occur in projects, in my experience a major setback is a much more likely event. My simulation skills are a lot stronger than my analytic skills so I tend to go first to Monte Carlo simulations and then look at the results to see if they line up with analytical models I might expect. I modeled your process as Vn = Vn-1 + Am + vol* norm.s.inv(rand()) in excel, where Vn is the next value, Vn-1 is the previous value, Am is the average change from period to period (~ 66) and vol is the sampled standard deviation stdev.s of the changes (~30). With that model, at period 30 you will tend to get around 2000, similar to your linear trend. Running that around 1000 different times and looking at the statistics for each step you can make some guesses. Bottom line, it looks like your +-1 sigma variations from a linear growth path are N * vol * .16, so for step 30 an average value of 1980 and 1 sigma variations of +-139. Using a log-normal distribution of variation the equation would be Vn = Vn-1 + Am – vol * (exp(-norm.s.inv(rand()))-1).
Best Regards, Vance
Vance,
Thanks for sharing your work.
Q – I assume you don’t believe in fractal pricing models (ie, Mandelbrot). Can you share your thoughts why?
Again, I appreciate you sharing your excellent work.
Pat Aungier
Houston
Hi Pat, I hadn’t heard of fractal pricing models. I did find this article https://www.mdpi.com/2227-7072/4/2/11/pdf related to it. Taking a glance at the paper it looks like it results in a power-law distribution–which will likely have fatter tails than the log-normal distributions my post is based on. The actual tails of stock market moves are certainly fatter than a simple constant volatility model would predict but for the purposes of my post, which is for typical markets, I think trying to factor in extreme events would result in forecasts that typically overestimate likely moves. My approach is intended for modeling typical markets and would not be appropriate if you are trying to do value-at-risk style calculations where the existence of the fatter tails is a key consideration.
Best Regards, Vance
Vance, pls ignore my last question. I found the answer in your article. How would I incorporate implied volatility into these equations? Thank you for your assistance.
Mike
Implied volatility is usually stated as an annualized number(e.g. 20%) so you should divide them by the square root of 252 to convert them to daily numbers. Then you can use the equations as-is. – Vance
Thank you Vance. How could I adjust the formulas for tighter confidence intervals, e.g. 50%?
Mike
Is there a software package that will compute these ranges for a given stock?
Hi Mike,
Not that I know of. Pretty easy to do in Excel. Compute geometric mean (GM) and volatility(vol) from historic data. Using the last 21 trading days is a reasonable compromise between responsiveness and long term behavior. Upper bound growth is Pstart * Exp(k*GM + sqrt(k)*vol) where k is trading days in the future and Pstart is the price the stock is at when you start your future progression, Lower bound is Pstart Exp (k*gm – sqrt(k)* vol). This is for 1 sigma bounds, reality will fall between those two ranges around 68% of the time.
Vance
Hi Vance
Do you have an example in excel? The GM formula does not work with negative values.
Thanks
Jorge
To compute the geometric mean in Excel: GM = (Pend/Pstart)^(1/N) -1 Where N = the number of periods, which is one less than the number of samples. For example for the sequences of prices 100,105,110,108 the number N would be 3.
— Vance